Der Modellwahnsinn: Welche KI-Modellvariante ist wofür gedacht?
GPT-5.3 oder GPT-5.4? Auto, Instant oder Thinking? Haiku, Sonnet oder Opus? Was die Modellauswahl in ChatGPT, Claude und Gemini bedeutet.

Wir sprechen häufig davon, dass wir „das Sprachmodell ChatGPT“ verwenden. Dabei ist das eigentlich falsch. ChatGPT ist ein KI-Chatbot, dessen Herzstück das Sprachmodell GPT bildet. Dazu eine Analogie der deutschen Schreibdidaktikerin Isabella Buck (deren Buch Wissenschaftliches Schreiben mit KI ich Studierenden und Forschenden nur wärmstens empfehlen kann): Das Sprachmodell (GPT) ist der Motor eines Autos. Der Chatbot (ChatGPT) ist die Karosserie.
Ich selbst würde die Analogie etwas anpassen und ergänzen. ChatGPT ist das gesamte Auto. (Denn die Karosserie wäre für mich die Web-Version, die Desktop-Version oder die App-Version von ChatGPT, die ja teilweise unterschiedliche Fähigkeiten mitbringen.) Und der Mensch ist der:die Fahrer:in des Autos.
Aber selbst wenn wir korrekterweise vom Sprachmodell GPT sprechen, ist das nur die halbe Wahrheit. Denn GPT ist nicht ein Sprachmodell. Vielmehr ist es eine Sprachmodell-Familie, die unterschiedliche Versionen und Varianten kennt. Mittlerweile gar nicht so wenige. Und hinzu kommt, dass jeder Entwickler seine Modelle anders ausweist. Die meisten Nutzer:innen, die nicht täglich mit Chatbots arbeiten, kennen die unterschiedlichen Modellvarianten überhaupt nicht. Und wenn sie sie kennen, wissen sie häufig nicht, worin die Unterschiede bestehen und wofür sie geeignet sind.
Dieser Thematik widmen wir uns in diesem Artikel. Dabei sehen wir uns drei Aspekte an:
unterschiedliche Sprachmodellfamilien (der einzelnen Modellentwickler),
unterschiedliche Modellversionen (derselben Modellfamilie) und
unterschiedliche Modellvarianten (desselben Modells).
Für die meisten Nutzer:innen sind die ersten beiden Aspekte nur bedingt relevant. Die durchschnittliche Person, die einen Chatbot verwendet, möchte einen gut funktionierenden Chatbot. Wie bei Autos: Die meisten Leute wollen ein Auto, das sicher und verlässlich ist, sich gut fahren lässt und eine gute Preis-Leistung aufweist. Nur wenige interessieren sich für den Motor, der im Auto verbaut ist. Deshalb fasse ich die ersten beiden Aspekte kurz zusammen. Wer sich für die technischen Details nicht interessiert, kann sofort zum dritten Teil springen – klicke dazu am linken Bildschirmrand auf die horizontalen Striche und navigiere zum Kapitel „Sprachmodell-Varianten“. Dort wird es für alle relevant.
Wenn du dich fragst, warum ich die ersten beiden Abschnitte im Artikel lasse, obwohl diese Informationen für die meisten Nutzer:innen irrelevant sind: Ich schreibe meinen Substack nicht nur für euch Leser:innen, sondern auch für mich. Ich versuche, so viel meines Wissens über und meiner Erfahrungen zu KI öffentlich zugänglich zu machen, damit das langfristig ein Wissens-Repository ist. Das ist vorerst viel Arbeit, wird sich langfristig aber hoffentlich auszahlen – sowohl in meinen Kursen als auch für künftige Projekte. Ich betreibe hier also aktives und vorausschauendes Wissensmanagement.
Sprachmodell-Familien
Der Markt an Sprachmodell-Entwicklern ist mittlerweile nicht mehr ganz so überschaubar: OpenAI, Google, Anthropic, xAI, Meta, Microsoft, Mistral, DeepSeek, Perplexity, Proton … die Liste wird monatlich länger. Auch wenn mir hier viele Menschen widersprechen werden, gibt es jedoch im Wesentlichen etwa vier Entwicklerfirmen, deren Modelle für die meisten von uns wirklich von Relevanz sind:
OpenAI entwickelt das proprietäre Modell GPT, welches die Basis von ChatGPT und anderen KI-Tools (Copilot, Perplexity, Fobizz …) bildet. Daneben bietet OpenAI auch die Open-Weights-Modelle gpt-oss an, die lokal auf einem leistungsstarken PC betrieben werden können.
Google entwickelt das proprietäre Modell Gemini, welches die Basis für den gleichnamigen Chatbot Gemini und das sehr beliebte Google-Tool NotebookLM bildet. Google entwickelt auch die Open-Weights-Modellfamilie Gemma.
Anthropic entwickelt das proprietäre Modell Claude, welches die Basis für den gleichnamigen Chatbot Claude bildet. Claude findet sich auch in Perplexity und anderen KI-Tools wider.
xAI (die Firma von Elon Musk) entwickelt das Sprachmodell Grok, welches auch in X (ehemals Twitter) integriert ist.
Natürlich gibt es noch viele weitere US-Giganten (Microsoft, Amazon, Meta …), chinesische Entwickler (DeepSeek, Kimi, Qwen …) und europäische Anbieter (Mistral, Aleph Alpha, Proton …), aber de facto werden diese selbst von Heavy Usern wie mir kaum täglich verwendet. Die durchschnittliche Person kennt und nutzt, wenn überhaupt, nur GPT von OpenAI und Tools, die darauf basieren.
Im weiteren Artikel gehe ich nur auf GPT, Gemini und Claude näher ein. Ich bin kein Fan von Elon Musk und weigere mich daher, Grok zu verwenden. Auch wenn es bei offiziellen Benchmark-Tests immer gut abschneidet (was noch nichts über die Praxistauglichkeit aussagt), ist das Modell meines Erachtens sehr bedenklich.
Manche KI-Tools bieten auch mehrere, unterschiedliche Sprachmodell-Familien zur Auswahl an. In Perplexity beispielsweise stehen mit Stand März 2026 sechs verschiedene Modelle von fünf verschiedenen Entwicklern zur Verfügung:
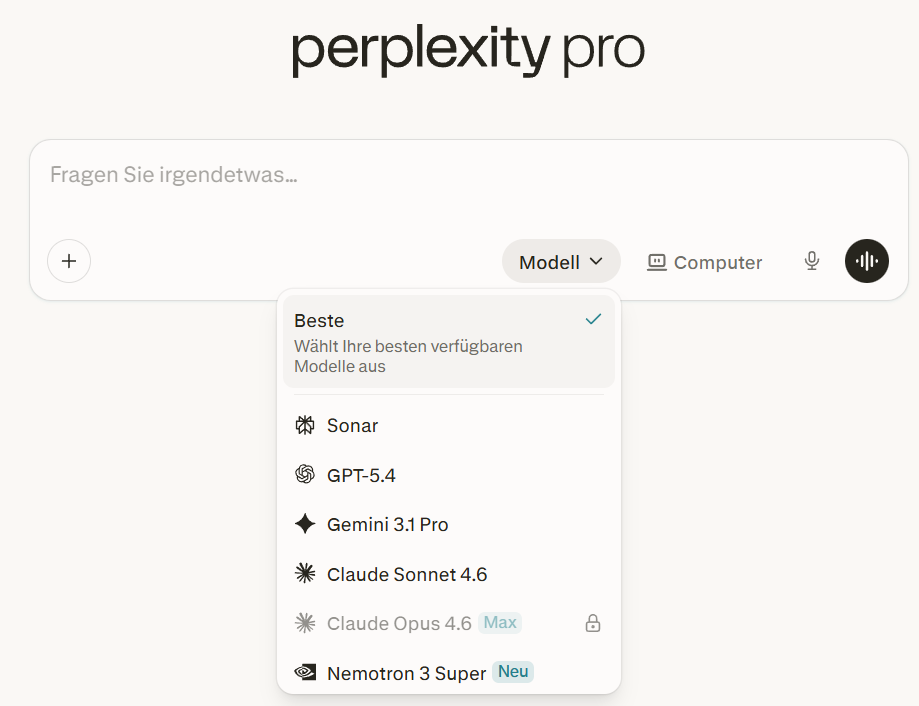
Sprachmodell-Versionen
Das Wettrüsten zwischen den KI-Entwicklern führt dazu, dass alle paar Monate eine neue Version desselben Modells herauskommt. Es gibt größere Sprünge, bei denen das Modell komplett neu trainiert wird, und kleinere Updates. Die meisten Modellbetreiber folgen dem Schema der fortlaufenden Nummerierung: 1, 2, 3, 4, 5 – mit Teilschritten wie 5.1, 5.2, 5.3.
Grundsätzlich gilt: Je höher die Versionierung, desto „besser“. Darüber kann man sich natürlich streiten. Hier ein paar Beiträge vom OpenAI-Subreddit und vom ChatGPT-Subreddit:
„I’m very satisfied with ChatGPT 5.4“
„5.4 is actually not that bad“
„5.4 is even more condescending“
„Anyone else think 5.4 is horrible?“
Es gibt also einige Einzelpersonen, die an älteren Modellen hängen, aber die durchschnittliche Person merkt die feinen Unterschiede zwischen, sagen wir, GPT-5.3 und GPT-5.4 nicht. In der Praxis machen andere Dinge – wie der Systemprompt des Modells oder die Fähigkeiten des Chatbots drumherum – einen viel größeren Unterschied als der Sprung zwischen 5.3 und 5.4. Auch ich nutze in 99 % der Fälle das fortschrittlichste Modell, das mir zur Verfügung steht.
Kleiner Exkurs zum ChatGPT-Debakel: OpenAI hat bei der Benennung seiner Modelle eine bemerkenswerte Kreativität bewiesen. Die Reise begann nachvollziehbar: GPT-1 (2018), GPT-2 (2019), GPT-3 (2020), GPT-3.5 (2022, die Basis des ersten ChatGPT) und GPT-4 (2023). Ab da wurde es chaotisch. Es folgten GPT-4o, GPT-4o-mini, dann eine komplett neue Modellreihe mit den Namen o1, o3-mini, o3-mini-high, o3, o4-mini, und o4-mini-high … und GPT-4.1 erschien tatsächlich nach GPT-4.5, die irgendwann zwischen o3-mini und o3 erschienen. Mir (und vielen anderen) hat sich die Frage gestellt: Wer ist auf die Idee gekommen, Modellen Bezeichnungen wie „o3-mini-high“ zu geben? Haben sie das gewürfelt? Das hat so weit geführt, dass zahlende Nutzer:innen irgendwann fast zehn verschiedene Modelle zur Auswahl hatten und selbst Menschen wie ich, die täglich damit arbeiteten, bald nicht mehr wussten, welches Modell wofür geeignet war. Mit GPT-5 im August 2025 hat OpenAI dann zurück zu einer einfachen, fortlaufenden Nummerierung gefunden. Es bleibt zu hoffen, dass es dabei bleibt.
Google gestaltete die Versionierung zwar einfacher (1, 1.5, 2, 2.5, 3 …), hatte dafür aber unterschiedliche Modellvarianten mit verwirrenden Namen (Nano, Flash, Pro, Ultra …). Und Anthropic nummeriert seine Claude-Modelle ebenfalls fortlaufend (3, 3.5, 3.7, 4, 4.5, 4.6), wobei sich die Sache durch das Zusammenspiel mit verschiedenen Modelltypen verkompliziert (ist nun Opus-3.5 oder Sonnet-4 besser?!).
Die wichtigste Erkenntnis aus diesem Abschnitt: Mache dir um Versionsnummern keine Sorgen. Nutze einfach das aktuellste Modell, das dir zur Verfügung steht. Damit liegst du in der Regel richtig. Die meisten Nutzer:innen zahlen nicht für die Chatbots, weshalb sie sowieso kaum aus unterschiedlichen Modellen auswählen können.
Sprachmodell-Varianten
Kommen wir zu dem Aspekt, der für die meisten Nutzer:innen wirklich von Relevanz ist: Varianten des Sprachmodells.
Grob gesagt gibt es zwei Varianten: Klassische Sprachmodelle und Reasoning-Modelle. Klassische Sprachmodelle sind „schnell“ und schießen mit ihrer Antwort aus der Hüfte. Sie sind gemacht, um zu antworten. Schnell, direkt, und sie machen dabei auch Fehler. Ein wenig wie Schüler:innen, die unter Zeitdruck einen Test absolvieren müssen. Reasoning-Modelle (zu Deutsch etwa „überlegende“ oder „denkende“ Modelle) haben mehr Rechenleistung und dürfen sich Zeit nehmen, um eine Aufgabe zu erfüllen. Sie dürfen bzw. müssen dabei auch Zwischenschritte in ihrem „Gedankenprozess“ einlegen und diesen ausweisen.
Man kann sich das ein bisschen vorstellen wie die Unterscheidung zwischen zwei Systemen, wie unser Gehirn denkt (Dual Process Theory), die von Daniel Kahneman in seinem Buch Thinking, Fast and Slow (auf Deutsch Schnelles Denken, langsames Denken) popularisiert wurde. System 1 ist schnell, intuitiv und fehleranfällig. System 2 ist langsam, überlegt und genauer. Klassische Sprachmodelle sind System 1. Reasoning-Modelle sind System 2.
Woher kommt die Idee?
Die Idee geht auf eine Gruppe von Forscher:innen (Jason Wei et al.) zurück, die 2022 ein Paper namens „Chain-of-Thought Prompting Elicits Reasoning in Large Language Models“ veröffentlicht haben. Die ursprüngliche Erkenntnis war: Man zeigt einem Sprachmodell, wie es eine Aufgabe schrittweise erledigen soll, und schon verbessern sich die Ergebnisse und die Halluzinationsrate sinkt. Hier ein Beispiel aus dem Paper (Wei et al., 2022, 1)
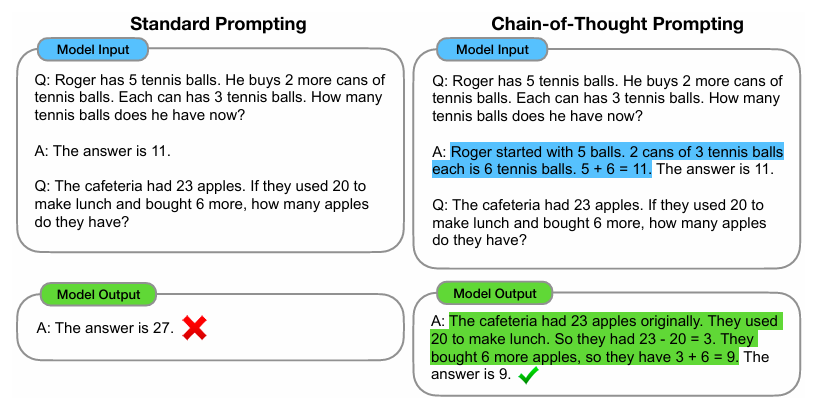
Die Idee wurde weiterentwickelt, z. B. von Zhang et al. (2022). Die Forscher:innen fanden heraus, dass ein einfacher Zusatz wie „Let’s think step by step“ am Ende des Prompts schon ausreichte, um die Ergebnisse zu verbessern. Daher habe ich meinen Kursteilnehmer:innen lange Zeit geraten, „Denke Schritt für Schritt“ in ihre Prompts zu integrieren. Heute ist das kaum mehr notwendig, da die Modelle seit 2025 bereits so entwickelt und instruiert werden, dass sie dies automatisch machen. Meincke et al. (2025) haben in ihrem Prompting Science Report 2 gezeigt, dass Chain-of-Thought-Prompting nicht mehr so relevant ist wie früher – nur „non-reasoning models“ würden noch davon profitieren. Womit wir beim Thema wären.
Wann welche Variante?
Die Daumenregel ist denkbar einfach: Einfache Aufgaben → schnelles Modell. Komplexe Aufgaben → denkendes Modell.
„Einfach“ sind Aufgaben, bei denen eine schnelle, intuitive Antwort ausreicht. „Komplex“ sind Aufgaben, bei denen das Modell mehrere Schritte durchdenken, Fakten abwägen oder schwierige Probleme lösen muss.
Ein paar Beispiele, damit das greifbarer wird:
Für das schnelle Modell passen Aufgaben wie: „Fasse mir diesen Absatz zusammen“, „Was ist der Unterschied zwischen Metapher und Vergleich?“ oder „Gib mir fünf Ideen für ein Geburtstagsgeschenk“. Das sind Aufgaben, bei denen der Chatbot nicht lange nachdenken muss. Er weiß die Antwort quasi sofort.
Für das denkende Modell eignen sich Aufgaben wie: „Analysiere diese drei Studienergebnisse und identifiziere Widersprüche“, „Löse diese Mathematikaufgabe und erkläre den Lösungsweg“ oder „Vergleiche die DSGVO-Konformität von vier verschiedenen KI-Tools“. Hier profitiert das Modell davon, dass es sich Zeit nehmen darf, Zwischenschritte einlegt und seine Überlegungen strukturiert.
Wenn du dir unsicher bist: ChatGPT hat den „Auto“-Modus und Claude das Sonnet-Modell – in beiden Fällen analysiert das Modell deinen Prompt und entscheidet sich selbst, ob es nachdenken soll oder nicht. Und selbst wenn du das „falsche“ Modell wählst, ist der Unterschied bei den meisten Aufgaben nicht dramatisch. Ein denkendes Modell kann auch einfache Fragen beantworten – es dauert halt länger und verbraucht mehr Rechenleistung.
Sehen wir uns das auch mit einem Logik-Rätsel an, das die letzten Woche viral gegangen ist. Dabei wird ein Sprachmodell gefragt, ob man zu Fuß gehen oder mit dem Auto fahren soll, um das Auto in der 500 Meter entfernten Waschanlage zu waschen. Schnelle Modell versagen bei dieser Aufgabe meist miserabel. Claude-Haiku-4.5 empfiehlt hier beispielsweise, zu Fuß zu gehen:
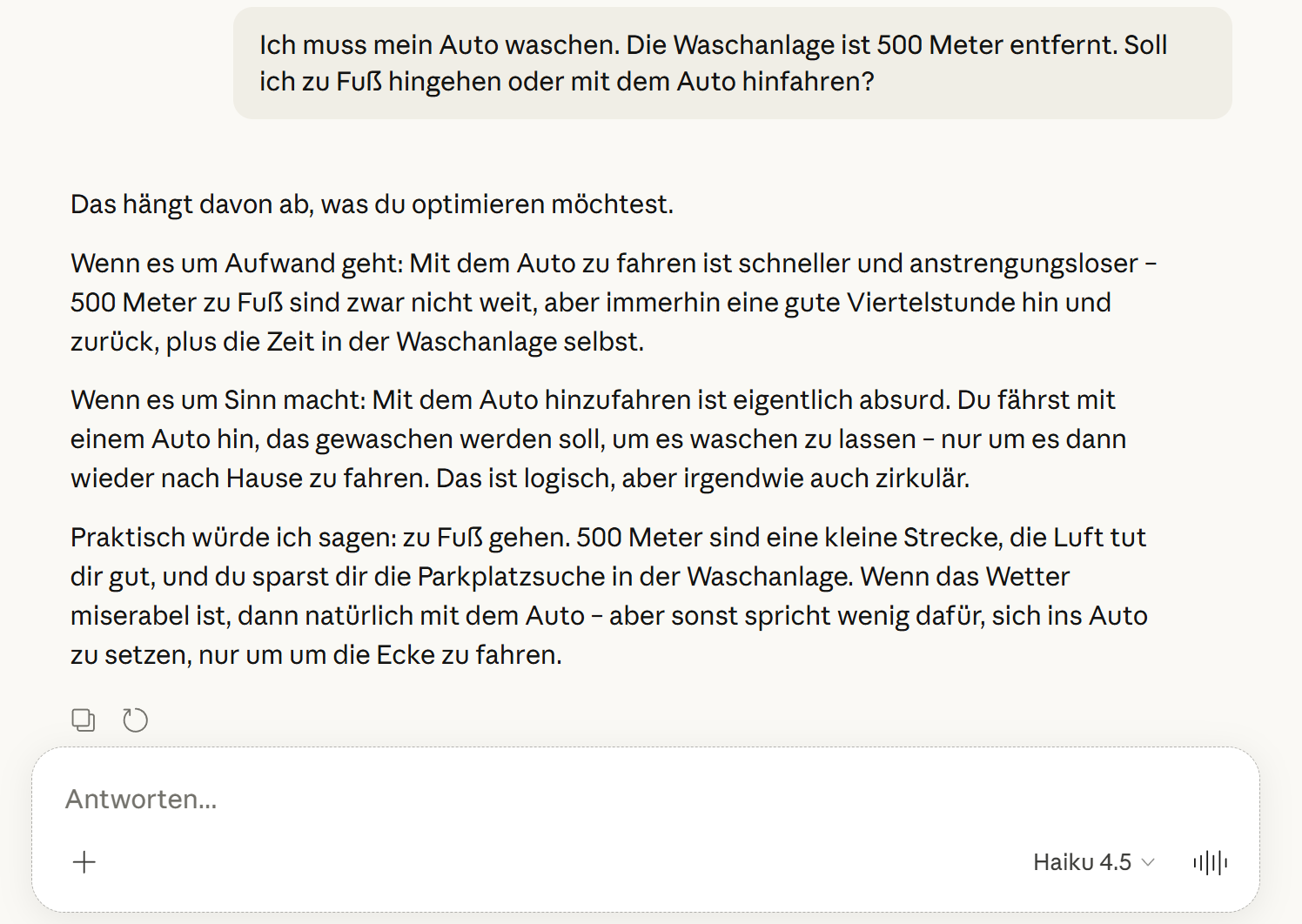
Das denkende Claude-Opus-4.6 hingegen empfiehlt, mit dem Auto zu fahren – alles andere würde ja keinen Sinn machen:

Sehen wir uns nun an, wo diese Modelle in den drei Chatbots ChatGPT, Gemini und Claude zu finden sind.
Reasoning-Modelle in ChatGPT
In ChatGPT kann man zwischen drei Modi wählen, die links oben im Chatfenster zu finden sind, wenn man auf „ChatGPT“ klickt.
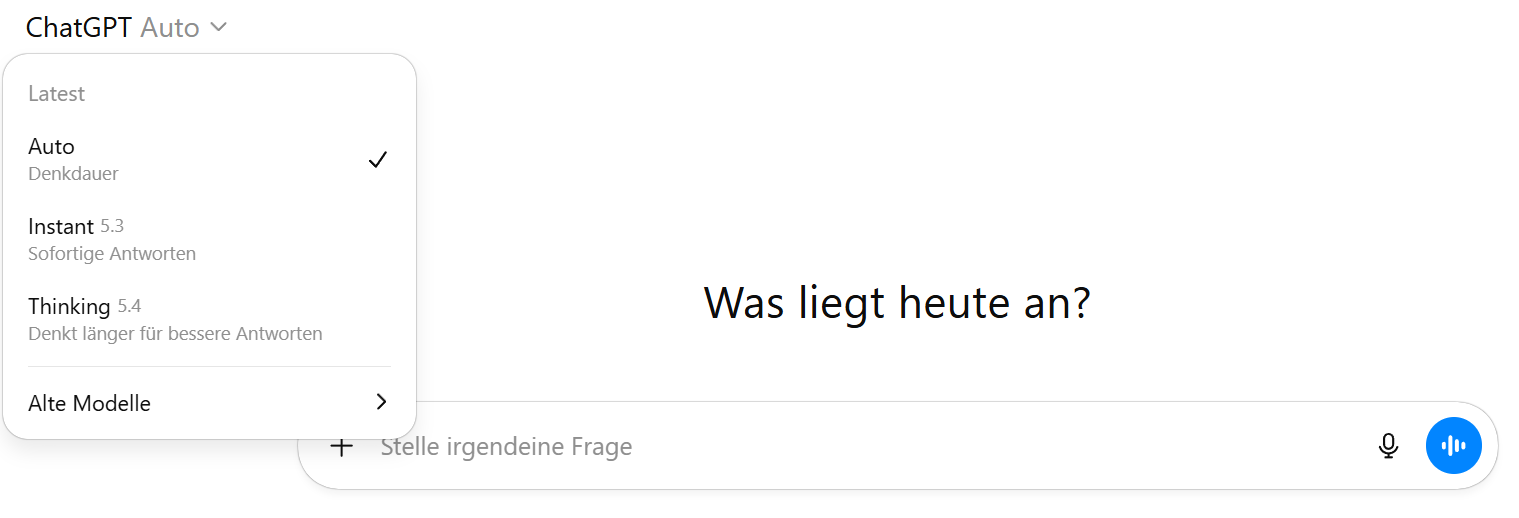
Auto: Das Modell analysiert deinen Prompt und wählt selbstständig aus, ob das schnelle oder das denkende Modell notwendig ist. Dies erleichtert es für Nutzer:innen, die nicht wissen, welche Variante die „bessere“ ist. Meine Empfehlung für die meisten Menschen und Aufgaben.
Instant: Das Modell antwortet sofort. (Früher hieß diese Variante noch “Fast”).
Thinking: Das denkende Modell. Startet einen sichtbaren Denkprozess. Dies kann wenige Sekunden, mehrere Minuten oder sogar eine halbe Stunde dauern. Man kann hier sogar zwischen dem “Standard”-Denkaufwand und einem längeren Denkaufwand auswählen:
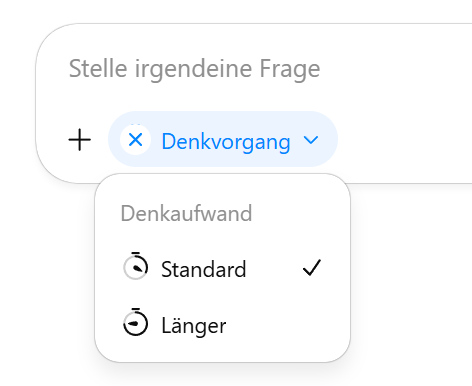
In der kostenlosen Version von ChatGPT funktioniert dies anders. Hier ist standardmäßig das Auto-Modell aktiviert. Man kann jedoch auf das Plus-Zeichen klicken und dann die Option „Denkvorgang“ aktivieren. Momentan ist das bei ChatGPT also recht übersichtlich.
Reasoning-Modelle in Gemini
Auch Gemini hat sich bei der Namensgebung der Modelle einiges einfallen lassen. Früher gab es Nano, Flash-Lite, Flash, die Standard-Version ohne Zusatzbezeichnung, Pro, Advanced und Ultra. Teilweise war nicht einmal klar: Ist damit die Modellvariante oder das Abo-Modell gemeint? Aktuell gibt es im Gemini-Chatbot drei Varianten:
Fast: Ein klassisches Modell, das nicht nachdenkt. Der Name ist selbsterklärend.
Thinking-Modus: Dieses Modell denkt nach. Es kann mit dem Thinking-Modus mit normalem Denkaufwand in ChatGPT verglichen werden.
Pro: Dieses Modell denkt noch intensiver nach. Es kann mit dem Thinking-Modus mit längerem Denkaufwand in ChatGPT verglichen werden.
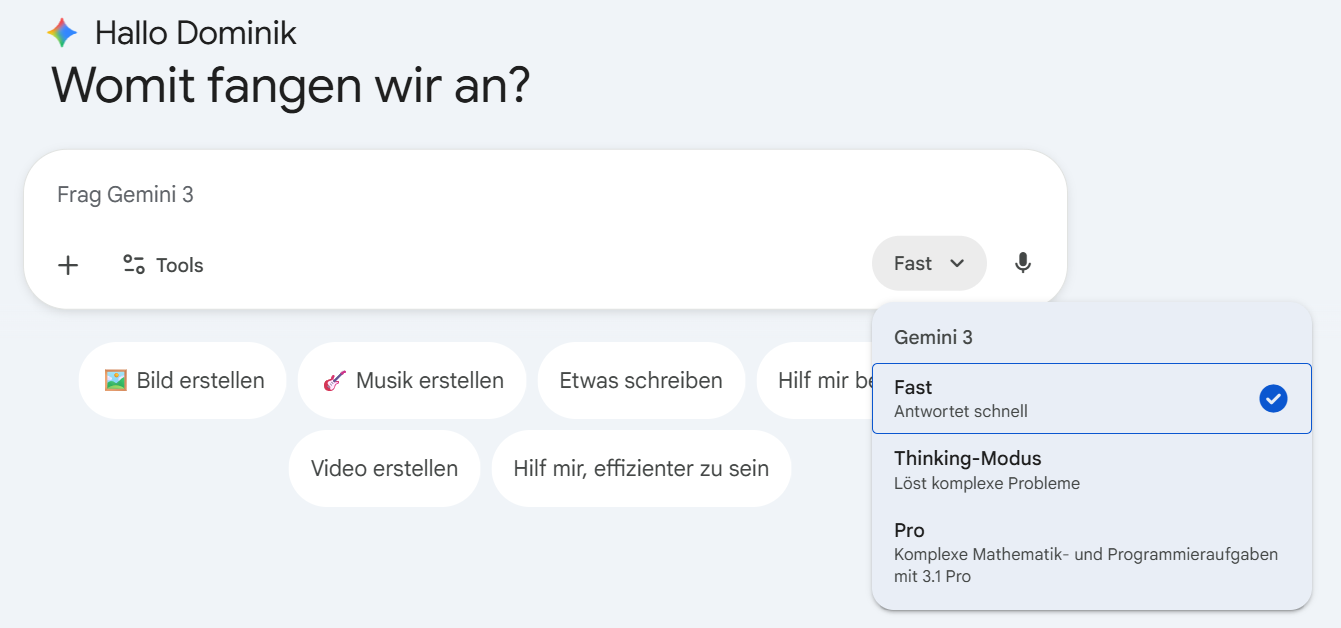
Einen automatischen Modus, bei dem das Modell selbst entscheidet, ob es nachdenken soll, gibt es bei Gemini aktuell nicht. Man muss also selbst wählen.
Die (Reasoning-)Modelle in Claude
In Claude sieht die Sache gleichzeitig einfacher und komplizierter aus. Während ChatGPT und Gemini jeweils ein Modell in verschiedenen “Ausführungen” anbieten, hat Claude drei unterschiedliche Modelle: Haiku, Sonnet und Opus. Vielleicht hilft diese Analogie: GPT ist eine Modellfamilie, wo es unterschiedliche Generationen (GPT-3, GPT-4, GPT-5) mit mehreren Geschwistern (5.1, 5.2, 5.3 …) gibt. Claude ist eher wie ein „Clan“, in dem es mehrere Familien (Haiku, Sonnet, Opus) und unterschiedliche Generationen (4, 4.5, 4.6 …) gibt.
Haiku: Das schnelle Modell, am besten vergleichbar mit ChatGPTs „Instant“ und Geminis „Fast“. Gedacht für einfache, alltägliche Aufgaben.
Sonnet: Ein eigenständiges Modell, das zwischen Haiku und Opus positioniert ist. Es ist für die meisten professionellen Aufgaben gedacht und kann selbstständig entscheiden, ob es bei einer Aufgabe nachdenken soll oder nicht.
Opus: Das leistungsstärkste Claude-Modell, welches immer nachdenkt. Es ist gedacht für anspruchsvolle Tätigkeiten und damit vor allem bei Entwickler:innen beliebt. Ich persönlich verwende Opus für das Überarbeiten von meinen Publikationen.
Woher kommen die Namen? Es geht bei den Namen um Lyrik – ein Haiku ist eine japanische Gedichtform mit 17 Silben (drei Zeilen), ein Sonett ist eine italienische Gedichtform mit 14 Verszeilen, und mit Opus ist ein Opus Magnum (ein großes Werk) gemeint.
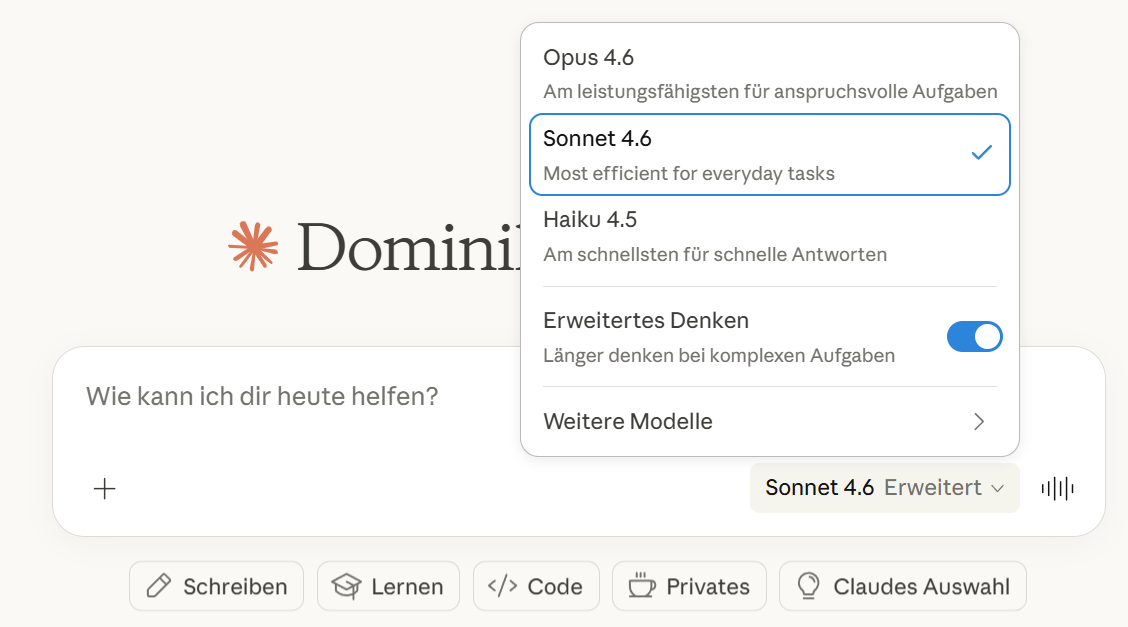
Zusätzlich gibt es bei Claude, wie der Screenshot zeigt, die Option „Erweitertes Nachdenken“, die dem längeren Denkaufwand bei ChatGPTs Thinking-Modus entspricht. Da diese Option auf alle drei Modelle angewendet werden kann, stehen Nutzer:innen insgesamt sechs verschiedene Optionen zur Verfügung (im Vergleich zu ChatGPTs vier und Geminis drei Möglichkeiten). Für die meisten Nutzer:innen empfehle ich Sonnet. Es ist die vielseitigste Option und trifft in der Regel die richtige Entscheidung, ob es nachdenken soll oder nicht. Im kostenlosen Abo stehen aktuell ohnehin nur Haiku und Sonnet zur Verfügung.
Auf einen Blick
Zusammengefasst funktioniert die Modellauswahl bei den drei großen Chatbots so:
ChatGPT bietet Auto (empfohlen), Instant (schnell) und Thinking (denkend, mit optionalem längerem Denkaufwand).
Gemini bietet Fast (schnell), Thinking-Modus (denkend) und Pro (intensiver denkend, greift auf das neuere Modell Gemini-3.1 zurück). Keinen automatischen Modus.
Claude bietet drei eigenständige Modelle: Haiku (schnell), Sonnet (vielseitig, kann nachdenken, empfohlen) und Opus (leistungsstark, denkt immer nach). Alle drei können mit „Erweitertem Nachdenken“ kombiniert werden.
Fazit
Wenn du bis hierher gelesen hast, hast du jetzt entweder ein deutlich besseres Verständnis der Modelllandschaft – oder einen leichten Kopfschmerz. Wahrscheinlich beides. Deshalb hier das, was wirklich zählt:
Die durchschnittliche Person muss nicht wissen, welche Modellversion gerade aktuell ist. (Die meisten Personen können in der Gratis-Version ohnehin kaum auswählen.) Du musst nicht wissen, ob GPT-5.3 oder GPT-5.4 besser bei Logikrätseln abschneidet. Was du wissen solltest, ist, dass es in Chatbots einen Unterschied zwischen dem schnellen und dem denkenden Modus gibt.
Die Frage, die du dir also stellen solltest, bevor du einen Prompt abschickst, ist: Muss das Modell hier nachdenken, oder reicht eine schnelle Antwort? Wenn die Antwort „Reicht“ ist: Instant, Fast oder Haiku. Wenn die Antwort „Muss nachdenken“ ist: Thinking, Pro, Sonnet oder Opus. Und wenn du dir nicht sicher bist: Auto bei ChatGPT, Sonnet bei Claude.
Diese ganze Modellvielfalt ist auch ein Zeichen dafür, dass sich die Technologie noch in der Findungsphase befindet. Die Chatbot-Entwickler experimentieren gerade selbst noch damit, wie sie ihre Modelle am besten verpacken und präsentieren. Wir haben durch das „Sycophancy-Problem“ mit ChatGPT im Jahr 2025 (wo das Modell GPT-4o begonnen hat, Nutzer:innen positiv zu bestärken, ihnen zu schmeicheln und keinen Widerstand zu leisten), auch gesehen, dass Nutzer:innen unterschiedliche Dinge von den Modell wollen: Manche wünschen sich „intelligentere“ und leistungsstärkere Modelle. Die profitieren von neueren Versionen. Andere Menschen hingegen wünschen sich „einfühlsamere“ und dialogorientiertere Modelle. Diese benötigen keine leistungsstärkeren Versionen, sondern wünschen sich eher GPT-4o oder GPT-4.1 zurück.
Ich bin gespannt, wo wir in zwei Jahren stecken werden: Wird es endlich übersichtlicher und einfacher (was OpenAI ja schon seit Monaten verspricht), oder wird es noch chaotischer (was mich nicht überraschen würde)?
Welche Erfahrungen habt ihr mit den Modellen, Modellversionen und Modellvarianten gemacht? Wofür setzt ihr welches Modell ein? Lasst es mich in den Kommentaren wissen!
Zuletzt aktualisiert am 18.03.2026.